引入 之前简单看过Dubbo基于SPI的“微核+插件”形式的架构模式 ,Dubbo因为这种架构模式使得扩展十分简单,另外Dubbo的框架分层 十分清晰,看起源码来相对轻松不少。
在使用Dubbo时突然想到几个问题,Dubbo默认使用tcp长链接,消费者们可能同时发起调用,提供者是怎样处理这些请求的?消费者和生产者之间链接如何复用?消费者和提供者之间几个长链接?要搞清楚这几个问题要从Dubbo的exchange和transport层来找答案。
exchange 信息交换层:封装请求响应模式,同步转异步,以 Request, Response 为中心,扩展接口为 Exchanger, ExchangeChannel, ExchangeClient, ExchangeServer
transport 网络传输层:抽象 mina 和 netty 为统一接口,以 Message 为中心,扩展接口为 Channel, Transporter, Client, Server, Codec
Dubbo在这两层提供了不同的实现,信息交换层默认的是自定义协议dubbo,传输层默认使用Netty。下面的一些探讨以Dubbo的默认配置为基础进行,可能因为Dubbo版本不同其中一些类名或者方法名称不一致,但不影响对其本身的理解。可借由具体实现更好的理解Dubbo的抽象分层。
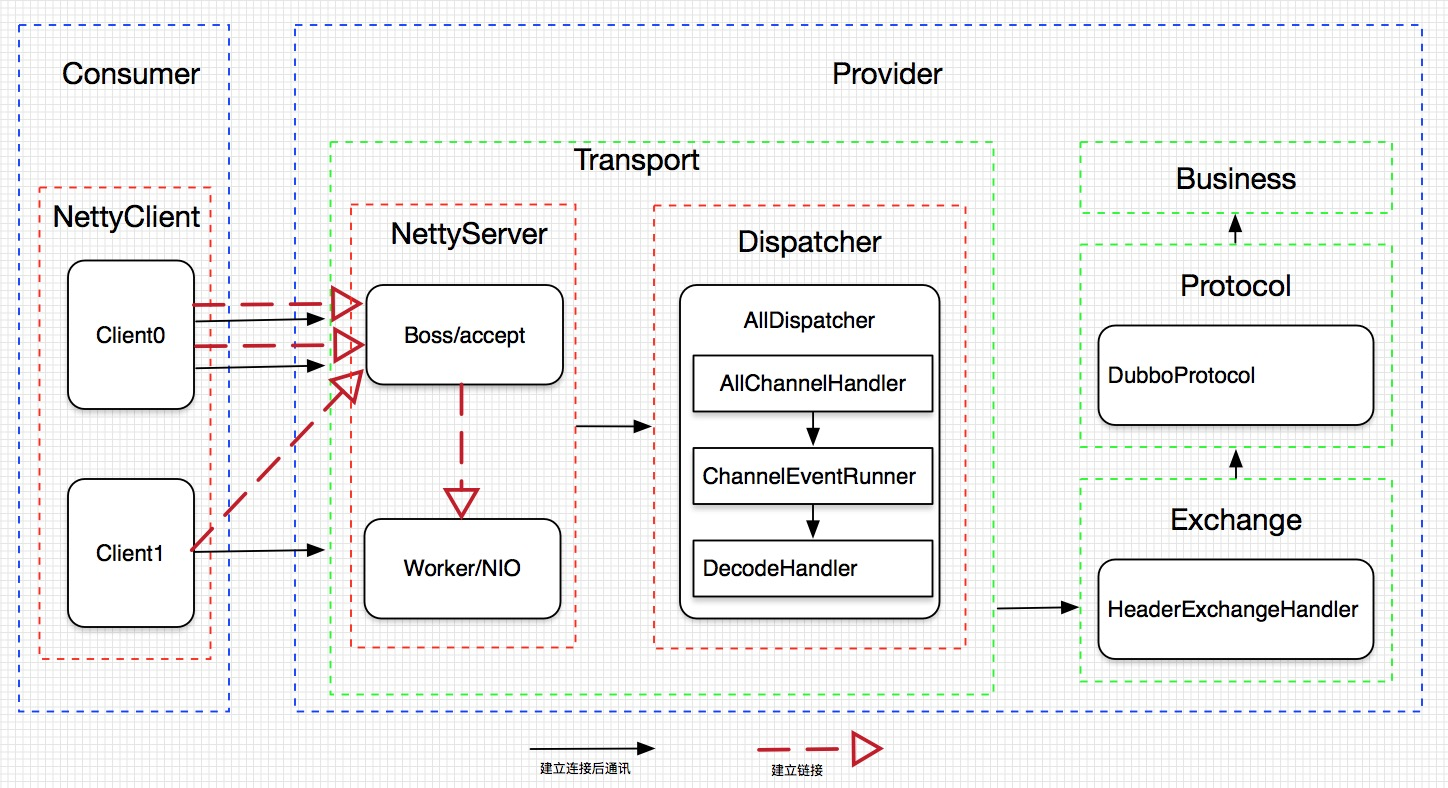
网络通信模型
Client表示应用具体的某个服务引用,每个服务的引用可根据提供者的配置(connections)建立多个链接。
在NettyServer中区分Boss和Woker的角色,Boss负责建立新链接,Woker负责链接建立后的IO工作,Woker的数量可由配置指定。
Dispatcher部分Dubbo按照不同场景提供了几种不同的实现,也可根据自身业务特点进行扩展。
all(默认) 所有消息都派发到线程池,包括请求,响应,连接事件,断开事件,心跳等。
direct 所有消息都不派发到线程池,全部在IO线程上直接执行。
message 只有请求响应消息派发到线程池,其它连接断开事件,心跳等消息,直接在IO线程上执行。
execution 只请求消息派发到线程池,不含响应,响应和其它连接断开事件,心跳等消息,直接在IO线程上执行。
connection 在IO线程上,将连接断开事件放入队列,有序逐个执行,其它消息派发到线程池。
上面提到的线程池指执行业务调用的线程池,此线程池可自行配置,默认为FixedThreadPool,大小为200,拒绝策略为AbortPolicyWithReport,队列为SynchronousQueue(不是很了解,后面再深入了解下)。上图中从ChannelEventRunner之后进入线程池。
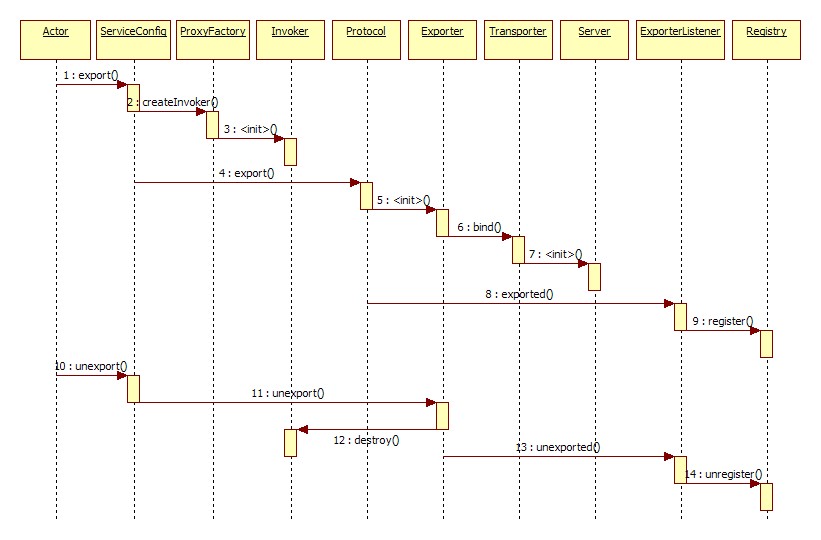
服务启动 Dubbo在解析service标签时会向外暴露服务,同时会检查打开网络服务。下图是dubbo服务暴露的时序图(摘自dubbo官网)。
在export阶段,会调用相应协议的export方法去完成invoker到exporter转化同时根据url(如下)中的address打开本地网络通信服务,默认启动netty服务。
1 2 3 URL内容 dubbo://10.1.87.93:20880/com.xx.IAdminUserLoginService?accesslog=/Users/childe/logs/access.log&anyhost=true&application=dmall-provider&connections=4&default.delay=-1&default.retries=0&default.service.filter=-monitor,-exception&default.timeout=10000&delay=-1&dubbo=2.5.9&generic=false&interface=com.xx.IAdminUserLoginService&loadbalance=roundrobin&logger=slf4j&methods=checkUser,getUserById,getUserByAccount&monitor=dubbo%3A%2F%2Fzk1.daily.com%3A2181%2Fcom.alibaba.dubbo.registry.RegistryService%3Fapplication%3Ddmall-provider%26backup%3Dzk2.daily.com%3A2181%2Czk3.daily.com%3A2181%26dubbo%3D2.5.9%26file%3D%2FUsers%2Fchilde%2F.dubbo%2FDDD-soa.cache%26logger%3Dslf4j%26owner%3Dmazha%26pid%3D21874%26protocol%3Dregistry%26refer%3Ddubbo%253D2.5.9%2526interface%253Dcom.alibaba.dubbo.monitor.MonitorService%2526pid%253D21874%2526timestamp%253D1528104644722%26registry%3Dzookeeper%26timestamp%3D1528104644709&owner=childe&pid=21874&revision=1.0.28&side=provider×tamp=1528104644712&uptime=1528104644716&version=1.0.0.fsm.chen
启动netty服务的代码如下,分别有boss和worker线程池供netty来完成新链接的建立及网络IO。在创建NioServerSocketChannelFactory时我们可以通过Dubbo的配置(dubbo:protocol 中iothreads)来指定IO的线程数量。默认数量为CPU可用核数加1,但不能超过32个。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 protected void doOpen () throws Throwable { NettyHelper.setNettyLoggerFactory(); ExecutorService boss = Executors.newCachedThreadPool(new NamedThreadFactory ("NettyServerBoss" , true )); ExecutorService worker = Executors.newCachedThreadPool(new NamedThreadFactory ("NettyServerWorker" , true )); ChannelFactory channelFactory = new NioServerSocketChannelFactory (boss, worker, getUrl().getPositiveParameter(Constants.IO_THREADS_KEY, Constants.DEFAULT_IO_THREADS)); bootstrap = new ServerBootstrap (channelFactory); final NettyHandler nettyHandler = new NettyHandler (getUrl(), this ); channels = nettyHandler.getChannels(); bootstrap.setPipelineFactory(new ChannelPipelineFactory () { public ChannelPipeline getPipeline () { NettyCodecAdapter adapter = new NettyCodecAdapter (getCodec() ,getUrl(), NettyServer.this ); ChannelPipeline pipeline = Channels.pipeline(); pipeline.addLast("decoder" , adapter.getDecoder()); pipeline.addLast("encoder" , adapter.getEncoder()); pipeline.addLast("handler" , nettyHandler); return pipeline; } }); channel = bootstrap.bind(getBindAddress()); }
Provider完成一次业务请求操作流程如下: 接收数据->AllChannelHandler->ChannelEventRunner->DecodeHandler->HeaderExchangeHandler->DubboProtocol::reply->Invoker::invoke->Impl
除了IO及具体业务的执行过程,一次处理最重要的就是数据的交换啦,即:请求数据根据协议转成对应的数据结构,业务相应数据也要根据协议进行转换。
下面这段代码起的便是承上启下的作用,在这个步骤中,根据Request的信息构造出Response,并调用具体协议的reply实现获取业务相应数据。
在构造Response时回写入了Request的ID和Version。这是channel复用的关键。每个channel的Request都有一个唯一的ID,类型为long。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 Response handleRequest (ExchangeChannel channel, Request req) throws RemotingException { Response res = new Response (req.getId(), req.getVersion()); if (req.isBroken()) { Object data = req.getData(); String msg; if (data == null ) msg = null ; else if (data instanceof Throwable) msg = StringUtils.toString((Throwable) data); else msg = data.toString(); res.setErrorMessage("Fail to decode request due to: " + msg); res.setStatus(Response.BAD_REQUEST); return res; } Object msg = req.getData(); try { Object result = handler.reply(channel, msg); res.setStatus(Response.OK); res.setResult(result); } catch (Throwable e) { res.setStatus(Response.SERVICE_ERROR); res.setErrorMessage(StringUtils.toString(e)); } return res; }
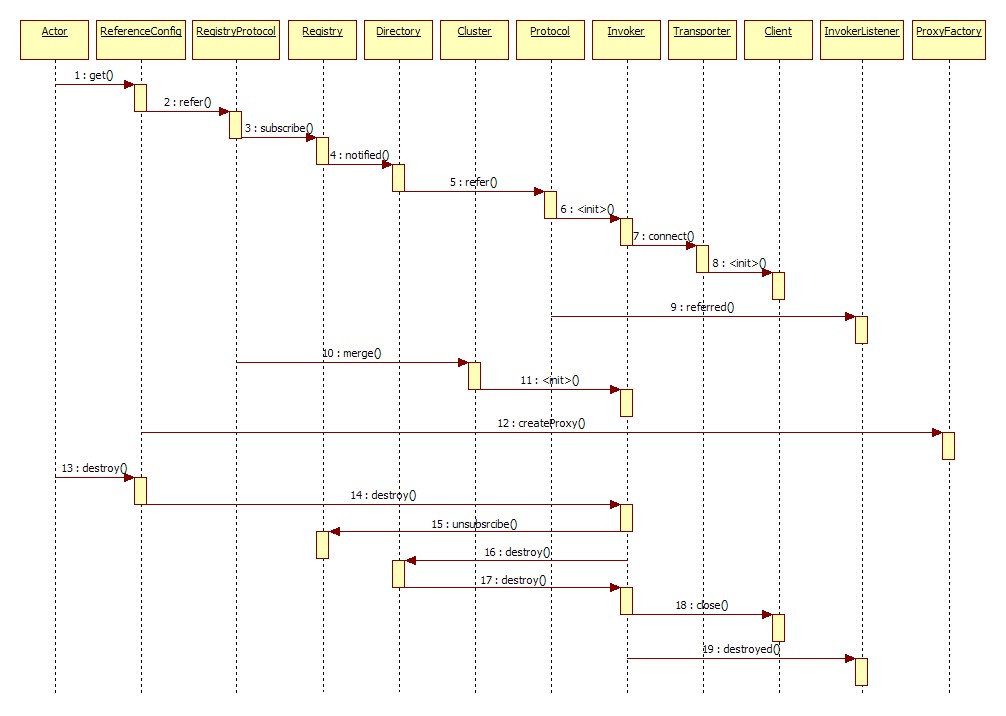
服务引用 Consumer启动时会从注册中心拉取订阅的Provider信息,并建立和Provider的链接,时序图如下(摘自dubbo官网):
Consumer的一次调用时序: DubboInvoker::doInvoke->NettyClient->AbstractClient::send->AbstractPeer->HeaderExchangeChannel::send->DefaultFuture::send->NettyChannel::send->DefaultFuture::received
Consumer每发起一次调用时会构建出本次调用的Request,每个Request有唯一的ID。Dubbo中用AtomicLong实现ID,短时间内不会重复,所以可作为唯一标识。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public ResponseFuture request (Object request, int timeout) throws RemotingException { if (closed) { throw new RemotingException (this .getLocalAddress(), null , "Failed to send request " + request + ", cause: The channel " + this + " is closed!" ); } Request req = new Request (); req.setVersion("2.0.0" ); req.setTwoWay(true ); req.setData(request); DefaultFuture future = new DefaultFuture (channel, req, timeout); try { channel.send(req); } catch (RemotingException e) { future.cancel(); throw e; } return future; }
1 2 3 4 5 6 7 8 9 10 11 12 private static final AtomicLong INVOKE_ID = new AtomicLong (0 );public Request () { mId = newId(); } private static long newId () { return INVOKE_ID.getAndIncrement(); }
Consumer发起调用后,使用DefaultFuture将异步变成同步,等待Provider的返回。当Provider有数据写回,我们将其转换为Response后,通过ID就可以知道通知哪个DefaultFuture来进行后续的处理了。这样就完成了channel的复用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public static void received (Channel channel, Response response) { try { DefaultFuture future = FUTURES.remove(response.getId()); if (future != null ) { future.doReceived(response); } else { logger.warn("The timeout response finally returned at " + (new SimpleDateFormat ("yyyy-MM-dd HH:mm:ss.SSS" ).format(new Date ())) + ", response " + response + (channel == null ? "" : ", channel: " + channel.getLocalAddress() + " -> " + channel.getRemoteAddress())); } } finally { CHANNELS.remove(response.getId()); } }
疑问回答
消费者和提供者之间长链接?
消费者和提供者之间几个长链接?
消费者和提供者之间连接如何复用?
官网释疑的几个问题
为什么要消费者比提供者个数多?
为什么dubbo协议不能传大包?
为什么采用异步单一长连接?
小生不才,以上如有描述有误的地方还望各位不吝赐教 !^_^!
参考及扩展链接 netty之boss-worker C10K问题 Dubbo框架设计 dubbo协议