引入
之前每次入门Disruptor对此部分总是泛泛看过,主要关注点在如何应用上,急于按照文档完成第一个Demo,怠慢了其实现的核心思想及其要解决的主要问题,导致虽然入门过几次Disruptor,仍对其认识十分浅薄。最近有空再次入门Disruptor时,不出意外的又遇到了难以规避的问题–内存的伪共享。
前车之鉴,后事之师。这次花了一些时间先去了解下久闻其名的伪共享。
Java对象内存估算
要想先搞清楚伪共享问题,就先需要搞清楚使用的语言(Java)对实例对象的内存布局以及如何来检测估算实例的内存占用。
Instrumentation
Instrumentation是Java SE5开始引入的,我们可以通过它来检测Java对象的大小,当然这只是Instrumentation强大功能之一,还可以通过Instrumentation增加自定义类转换器,对Class进行增强或者替换,只是我们在这里并不关心。
找到了检测工具后怎么去使用呢?
首先,要获取Instrumentation实例。Instrumentation由虚拟机来实例化和维护的,可以通过两种方式来获取:
当JVM以指示一个代理类的方式启动时,将传递给代理类的premain方法一个Instrumentation实例。
当JVM提供某种机制在JVM启动之后某一时刻启动代理时,将传递给代理代码的agentmain方法一个Instrumentation实例。
这里通过方法一来做。
步骤1. 创建一个用来检测对象大小的工具类,并在该类中声明实现premain方法;
1 | public class ObjectSizeUtil { |
步骤2. 利用javaagent方式启动来获取Instrumentation实例。这里以IDEA为例使用maven插件的方式来配置javaagent。
| 插件名 | 功能简介 |
|---|---|
| maven-jar-plugin | maven 默认打包插件,用来创建 project jar,可参考下一些开源软件项目对该插件的使用,比如:dubbo |
| maven-shade-plugin | 用来打可执行包,包含依赖,以及对依赖进行取舍过滤,可参考下一些开源软件项目对该插件的使用,比如:dubbo |
| maven-assembly-plugin | 支持定制化打包方式,更多是对项目目录的重新组装,可参考下一些开源软件项目对该插件的使用,比如:dubbo |
1 | <plugin> |
配置完成后使用maven进行打包。
步骤3. 在启动脚本中增加代理类路径,我的是-javaagent:/Users/childe/Documents/workspace/goodGoodStudy/target/childe-1.0-SNAPSHOT.jar
完成上面的操作后,基本工具就完成了,接下来就使用Instrumentation来帮助我们获取对象内存大小。
对象大小检测
在估算内存大小时,会遇到类似Retained heap和Shallow heap两个概念,Shallow heap表示一个实例自身占用堆空间的大小,而Retained Heap不仅包含自身占用堆空间还包括自身引用其他对象的Shallow heap。在MAT中Retained Heap是一个对象被GC回收时,能够释放其所有引用的Shallow Heap的总和。
在开始检测前,先回顾下Java中元类型的大小。
| 类型 | 大小(字节byte) |
|---|---|
| byte | 1 |
| short | 2 |
| int | 4 |
| long | 8 |
| float | 4 |
| double | 8 |
| char | 2 |
| boolean | 大小没有明确指定,和虚拟机具体实现有关 |
一个类的实例对象在内存中这么分布:对象头 + 实例数据 + 填充。对象头里面保存了对象相关的诸如GC标记、锁标记等一些必要信息,实例数据就是对象的各个属性,填充是为了让对象的大小为8的倍数。
在开启指针压缩(-XX:+UseCompressedOops)的情况下,测试了一些元类型的大小。
1 | // 64位机器上reference类型占用8个字节,开启指针压缩后占用4个字节 |
当然,还有array、reference、String(特别的)类型内存大小的测试,这里不一一列出,全部代码->请戳这里-<。
伪共享
缓存
说到伪共享就不得不提一下CPU和高速缓存。我们知道,CPU的计算速度时远远大于磁盘的读写速度的,为了缓解两者之间的速度差,就有了内存,CPU计算时需要的数据先放到内存中,CPU直接操作内存的数据而不是操作磁盘,内存又分成几部分:一级缓存(L1)、二次缓存(L2)、三级缓存(L3)、主存(Main Memory)。
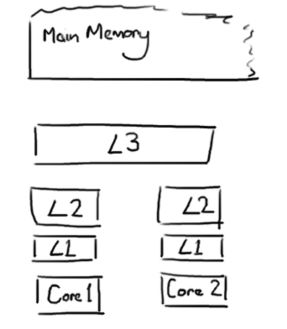
如图所示,越靠近CPU的缓存速度越快,容量就越小。当CPU执行运算的时候,它先去L1查找所需的数据,再去L2,然后是L3(被单个插槽上的所有CPU核共享),最后如果这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果在做一些很频繁的事,就要确保数据在L1缓存中。
缓存行
数据在缓存系统中是以缓存行(cache line)为单位存储的。缓存行是2的整数幂个连续字节,一般为32-256个字节。最常见的缓存行大小是64个字节。当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
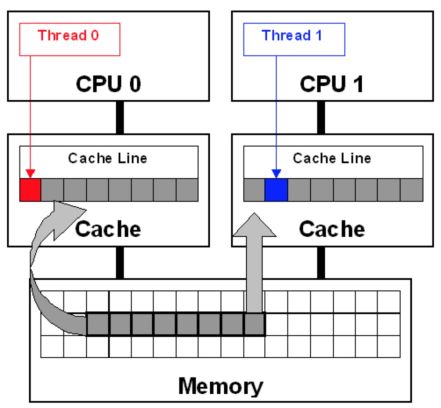
如上图,为了简化问题,把缓存表示成了一块。线程0和线程1会用到不同变量,它们在内存中彼此相邻,并驻留在同一高速缓存行。高速缓存行被加载到CPU0和CPU1的高速缓存中(灰色箭头)。尽管这些线程修改的是不同变量(红色和蓝色箭头),高速缓存行仍会无效(MSEI协议),并强制内存更新以维持高速缓存的一致性。
那么,伪共享的存在到底对我们的程序有多大影响呢?我们做个->测试(戳我看源码)<-看下。
以下测试数据环境:1
2
3
4
5
6CPU 2.7 GHz Intel Core i5
内存 8 GB 1867 MHz DDR3
java version "1.8.0_74"
Java(TM) SE Runtime Environment (build 1.8.0_74-b02)
Java HotSpot(TM) 64-Bit Server VM (build 25.74-b02, mixed mode)
1 | public final class FalseSharing implements Runnable { |
上面代码在disruptor用户手册中文翻译中有所描述,查看了网络上的一些关于伪共享的文章,测试代码大同小异,但VolatileLong这个类中,网上大多写的是填充6个long类型的属性,但经过计算和测试,基于上述代码环境时填充5个才是合适的,大家在做实验的时候注意一下自己的环境问题,这也是为什么文章开头先介绍计算对象大小的原因。
在VolatileLong类的注解中我贴出了自己跑的几组数据,得出的结论和我们的分析时一致的,伪共享随着竞争的加剧,表现的更加明显。
总结
在Java8之后,新增了注解@sun.misc.Contended,来避免伪共享的问题,在JDK的源码中也可以搜寻到她的身影,像我们常用的Thread和ConcurrentHashMap中都有使用该注解。
那么是不是我们编码时要特别关注伪共享这个问题呢?个人认为除非是真的是要追求卓越的性能表现,大可不必在普通的业务应用中过分考虑该问题。首先,这个问题很隐蔽,难以从系统层面上通过工具来探测伪共享事件;其次,做测试之前我也强调了自己的测试环境,这个问题实际上和环境也有一定的关系;另外,缓存资源是很珍贵的,这些事情我们毕竟不专业,如果滥用就造成了浪费;最后,像Intel这类的厂商在做设计时必然会对此类问题做优化。所以呢,我们只要在真正需要时去考虑这些问题就行了。
终于把Disruptor一大优势-避免伪共享的基础了解完了,可以继续了解它在RingBuffer中精巧的无锁设计了!
小生不才,以上如有描述有误的地方还望各位不吝赐教 !^_^!
参考
java对象内存分布(Java Memory Layout)