背景
项目中存在以下场景需要延迟触发一些事件:
- 订单在未支付状态下30分钟后自动关闭;
- 订单超过15天未主动确认收货需要自动确认收货;
- 商品价格需要在不同的时间段生效不同的价格方案等。
以上场景下需要有一个相对平台化的服务来满足,而不必每个项目自己做定时任务去进行轮询。
解刨延迟/定时任务
构成一个任务有两个要素:执行时间;执行逻辑。对任务规划者而言,并不关心任务执行逻辑,规划者只要在既定的时间触发该任务,但既然作为一个规划者,就必须具备任务的基本维护能力:新增,删除/取消,到期,查找。
那么一个想要实现规划者就必须考虑两件事:1.怎样即时发现时间到期;2.怎样提高任务的维护效率,即怎么存储任务来保证对任务的高效操作。
本文只关注延时队列中对任务的基本规划能力的实现方式,不涉及延时系统的设计讨论,系统层面的话题太大了。
Rocketmq延迟队列实现
Rocketmq的定时队列通过一个叫做“SCHEDULE_TOPIC_XXXX”的Topic来实现,这个Topic用来处理需要被延迟发送的消息。在Rocketmq中延迟消息被分为几个延迟级别,每个延迟级别分别对应“SCHEDULE_TOPIC_XXXX”Topic下一个延迟队列,默认延迟级别为:”1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h”。在Broker启动时,会启动相对应队列的线程来处理各个延迟队列的延迟消息。
盗用艾瑞克一次分享中的图来直观感受下延迟队列的实现。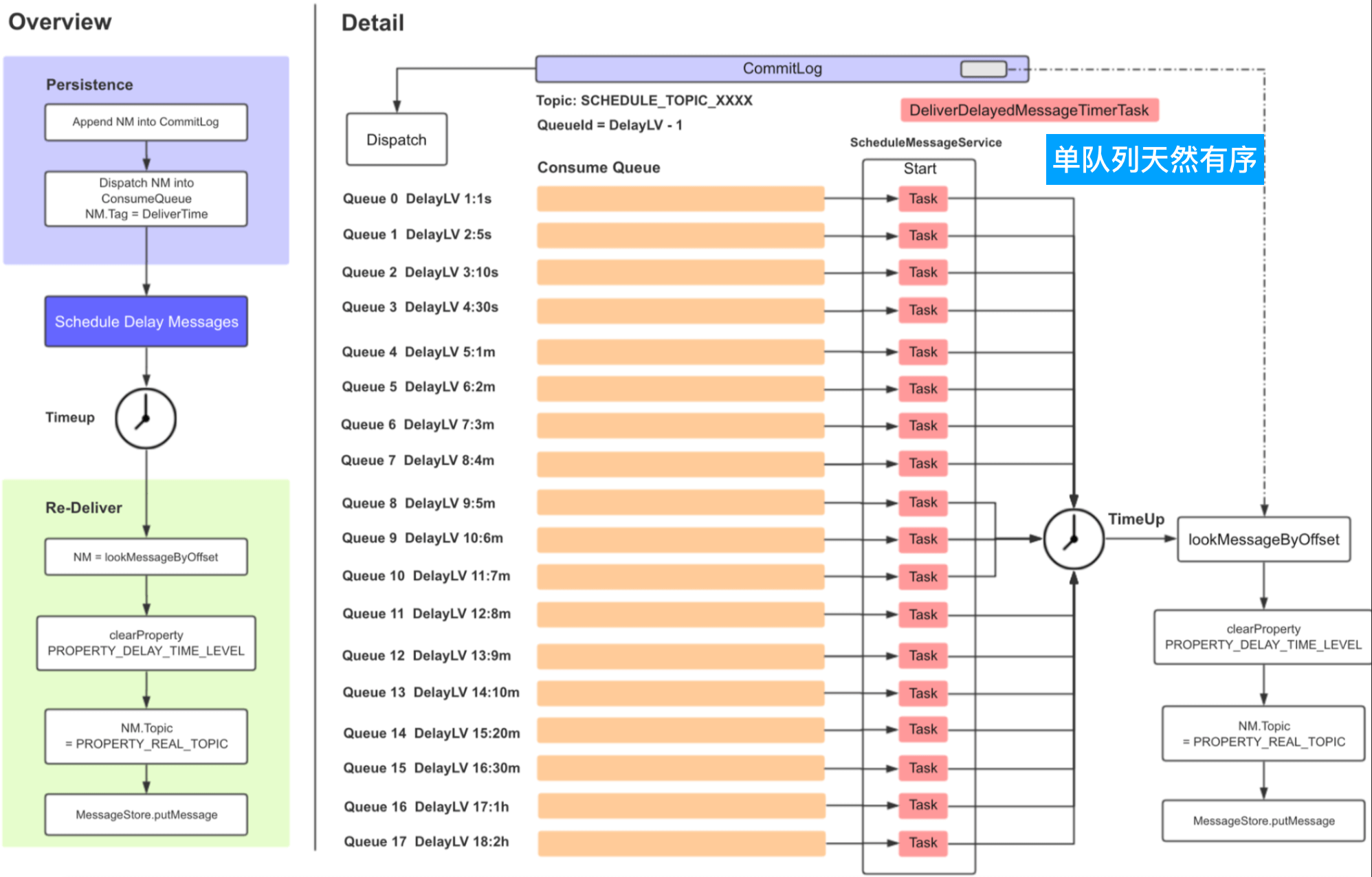
Rocketmq处理通过消息体的扩展字段DELAY来区分Producer是否投递的是延迟消息,如果DELAY大于0,即确定是延迟消息,Broker会备份源消息的topic和queueId,并将其替换为对应延迟队列的信息,然后将修改后的消息落盘到commitLog,DefaultMessageStore#ReputMessageServiceReput线程将消息分发至对应Topic的消息队列(messageQueue),延迟队列被ScheduleMessageService消费,延迟消息到期后会被封装为一个新消息(恢复其源Topic及queueId等信息)再次走消息的投递流程到commitLog,然后被Reput到最初要投递的队列,在整个过程中ScheduleMessageService同时扮演了Consumer和Producer的角色,区分好这两种角色后再来看ScheduleMessageService这段代码会清楚不少。下面列出的代码有所删减改,目的是为了表达核心逻辑。
1 | // ScheduleMessageService |
此种方式数据结构类似链表,但链表中的数据天然有序,为什么呢?因为消息的延迟时间是Broker落盘时间加上延迟级别对应的时间,落盘后的消息才会被ReputMessageServiceReput线程进行分发到指定的MessageQueue,而Reput线程是个单线程,整个过程FIFO,所以延迟队列天然有序。
我们再从任务的行为:新增,删除/取消,到期,查找,来看下Rocketmq延迟队列作为任务的优缺点。
- 因为Rocketmq的设计方式,注定其延迟队列只能支持特定延迟时间的特点;
- 因为Rocketmq并不是为延迟任务而生,所以它无法删除/取消一个定时任务;
- 生产一个延迟消息和生产一个普通消息的过程是一致的,因此新增一个延迟消息无非就是像broker进行消息投递,如果网络稳定,其时间消耗稳定;
MessageQueue的天然有序,保证队列头的消息一定是最先到期的,所以到期任务的检索时间稳定;- 消息的查找只可根据msgId查找或者消息key查找,msgId中包含消息的物理偏移量(类似MySql的主键)可直接定位消息,而key的查找是根据key的hashCode查找索引文件获得,可能或出现查出多条的情况,需要客户端自己根据key再次过滤,除了在控制台很少在Consumer端使用key发起查询。
个人认为虽然Rocketmq具备延迟的功能,但其主要目的是为了实现“至少投递一次”语义,因为一个延迟消息处理完成会被Rocketmq落盘两次,就只是因为topic和queueId不同,如果Rocketmq只用来处理延迟消息,那么其存储的数据量延迟消息的两倍。所以如果延迟消息量不是很大并且不需要灵活的延迟时间的话,Rocketmq不失为一种好的选择。
DelayQueue
在JDK中带有定时/延迟特性的两个类:DelayQueue和ScheduledThreadPoolExecutor。这两个类名起的很好,见名知意。我们从这两个类的数据结构入手看下JDK这两个自带类如何实现任务的规划。
DelayQueue内部使用PriorityQueue来存储定时/延时任务,相当于是PriorityQueue的一种使用场景,主要特性是当队列为空或任务时间未到期时可让拉取线程进行等待。
PriorityQueue使用二叉堆来存储数据,这里不去深究二叉堆的定义,其特性是根节点一定是整个堆中最大/最小的点,这点是比较符合优先队列的特性,PriorityQueue的根节点queue[0]是最小的节点,称为最小堆。PS:二叉堆是完全二叉树或者是近似完全二叉树。
| 完全二叉树 | 满二叉树 | |
|---|---|---|
| 总节点k | $$2^{h-1}<= k <= 2^{h}-1$$ | $$2^{h}-1$$ |
| 树高h | $$h=log_{2}k+1$$ | $$h=log_{2}(k+1)$$ |
PriorityQueue用数组来实现二叉堆,queue[n]节点的两个子节点存储在queue[2*n+1]和queue[2*(n+1)],使用指定的Comparator或节点本身实现比较接口Comparable来排序。站在DelayQueue的角色来看,PriorityQueue的排序关键字是到期时间,比较器Comparator/Comparable比较的就是延迟时间的大小。
PriorityQueue关键操作的平均时间复杂度:增加O(log(n)),查找O(n),删除=查找+移除O(n) + O(log(n)),到期任务检索O(1)。PS:就二叉堆本身而言还有堆合并等操作,而且不同构造方式的时间复杂度也不相同,但不是这里的关注重点。
1 | // PriorityQueue |
在JDK中使用ScheduledThreadPoolExecutor同样使用了最小堆来规划任务,但与PriorityQueue不同,ScheduledThreadPoolExecutor对任务元素进行了优化,让任务本身持有自己在数组中的index,这样将取消操作时间复杂度降到了O(1),但如果removeOnCancel参数配置为true时,取消操作会引起删除操作,此时就增加了堆的维护。该配置默认为false,这延迟了垃圾回收,会导致无谓的内存占用,前提是任务存在极大可能在开始前被取消。
1 | // ScheduledThreadPoolExecutor内部类 |
TimeWheel
以上两种实现方式有一个共同点,他们并没有按照预想将任务和延迟时间分离,接下来我们要讨论的时间轮就是按照这个思路来实现任务的规划,看一下时间轮如何来存储和存储/规划任务。
网上盗图来直观感受下时间轮。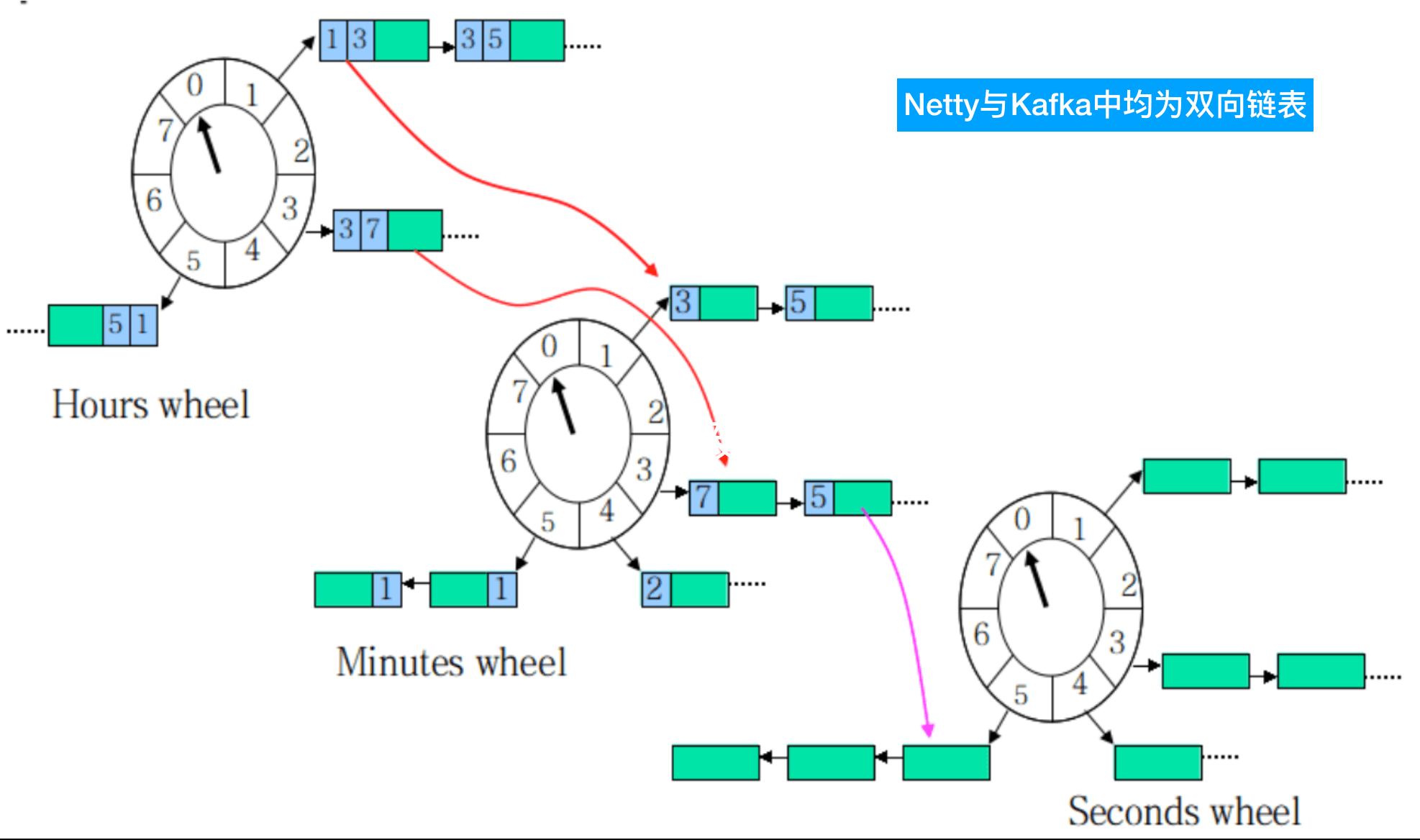
上图展示的一个多层时间轮,红线部分表示任务随时间流逝迁移的过程,直到最后被执行。
时间轮是对时钟的一个模拟,在时间轮中有以下几点需要注意:
- Tick,一次时间推进,每次推进会检查/执行超时任务。
- TickDuration,时间轮推进的最小单元,每隔TickDuration会有一次Tick,它决定了时间轮的精确程度。
- Bucket(TicksPerWheel),上图中的每一隔就是一个Bucket,表示一个时间轮可以有多少个Tick,它是存储任务的最小单元。
- 上层时间轮的TickDuration是下层时间轮的表示时间的最大范围,即:父TickDuration = 子TickDuration * 子Bucket梳理
Netty和Kafka使用时间轮来管理超时任务,因为具体场景不同实现也不同。
Netty
Netty的时间轮用来管理网络连接的超时,实际应用过程中网络超时时间一般不会很长,Netty采用单时间轮来规划超时任务。
1 | public class HashedWheelTimer implements Timer { |
上面是Netty时间轮主要的数据结构,从源码中我们可以看出Netty为提升效率废了不少心思,比如:PlatformDependent.newMpscQueue()来特定解决多生产单消费的场景,有兴趣的可以看下,这不是本文重点。
前面我们说了,Netty是单时间轮,当规划的任务时间超过一圈怎么办呢?我们看到超时任务HashedWheelTimeout中有一个remainingRounds字段,这个字段记录了该任务在被遍历多少次时可以被过期,任务每被遍历一次该字段值减1,当其值不大于0时,表示可以被过期。
Netty使用数组 + 双向链表的方式来组织时间轮,对于添加/取消操作仅做了记录,真正的操作实际发生在下一个Tick。我们来看下Netty版的时间轮对任务规划的时间复杂度。
添加任务
通过
newTimeout方法新增任务,Netty仅仅把任务放到timeouts链表的队尾,时间相对稳定,可看作O(1)。取消任务
取消是
HashedWheelTimeout任务本身提供的,在调用HashedWheelTimeout#cancel()方法后,Netty仅仅修改了任务状态并把任务放到了cancelledTimeouts链表的队尾,时间相对稳定,可看作O(1)。删除任务
1
2
3
4
5
6
7
8void remove() {
// 当前任务被规划到的Bucket,如果不存在说明尚未被规划,直接忽略
HashedWheelBucket bucket = this.bucket;
if (bucket != null) {
// 从bucket的链表中移除
bucket.remove(this);
}
}外部不暴露该操作,发生在过期任务时,由
HashedWheelTimeout任务本身提供,因为任务本身有记录当前的Bucket,所以删除操作等于是链表的一个删除操作,时间相对稳定,可看作O(1)。查找任务
不存在该场景。
过期任务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26// 时间推进线程
private final class Worker implements Runnable {
private long tick;
public void run() {
do {
// 获取本次过期时间
final long deadline = waitForNextTick();
if (deadline > 0) {
// 本次Bucket位置
int idx = (int) (tick & mask);
// 将 cancelledTimeouts 中任务从Bucket中删除
processCancelledTasks();
HashedWheelBucket bucket = wheel[idx];
// 将 timeouts 中的任务添加到对应的Bucket中
transferTimeoutsToBuckets();
// 遍历当前Bucket,执行当前Bucket中的过期任务
bucket.expireTimeouts(deadline);
// 记录嘀嗒次数
tick++;
}
} while (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_STARTED);
}
}时间的推进是独立的一个线程在做,该线程同时也负责过期任务的执行等操作,可简单认为此步骤操作为O(n),因为推进线程需要完全遍历
timeouts、cancelledTimeouts与bucket链表,在遍历timeouts时,Netty为了避免任务过多,所以限制每次最多遍历10万个,也就是说,一个tick只能规划10万个任务,当任务量过大时,会存在超时任务执行时间延迟的现象。
我们上面有说到取消任务时,只是将任务放在了超时链表中,在下次发生时间推进时才会真正将被取消的任务从队列移除,这就导致空间的浪费,GC回收会至少延迟一个推进间隔(TickDuration)。
如今Netty在网络通信中的霸主地位不必多言,虽然Netty中时间轮的实现不是最好的但一定是满足了Netty这个特定场景的性能需要,即:没有最好的技术,只有适合的技术。这一点对平时开发设计也有借鉴意义。
Kafka
Kafka也使用数组 + 双向链表的方式来组织时间轮(Timer.scala),只是有多个数组来表示多层时间轮而已,所以其对任务的增加/删除/取消操作实际也就是对双向链表的增删操作,时间复杂度与其一致,其到期任务的过程下面我们与Netty做比较来看。
上面关于Netty实现的一些比较蛇皮的地方,在Kafka中均得到了解决,并且Kafka中使用JDK中的DelayQueue来帮助做时间推进,使得一个线程可以轻松管理错层时间轮的时间推进。
我们先来看他规避了Netty中哪些不太合适的地方:
Netty单层时间轮规划超过一轮的任务时使用
remainingRounds来做控制,这就导致在一次推进中,当前Bucket下的任务并不是全部都是过期的,而Kafka使用多层时间轮,一个Bucket被某次推进选中,它下挂的任务行为完全一致,处理起来相对简单,Kafka目前也是由推进线程来遍历到期任务,但它也可以方便的使用fork/join方式来进一步提高处理效率。Kafka虽然也由推进线程遍历到期Bucket下的任务,但任务的执行却交给专门的线程池来执行,自己仅将该Bucket下的所有任务重新走一遍添加逻辑,以便决定任务是交给线程池执行还是下降到下层时间轮。
Kafka既然是多层时间轮,那他是如何来推进每个时间轮的时间呢?Kafka在时间推进层面跳过了时间轮这一层,直接规划到时间轮下的Bucket,Kafka将所有Bucket放在DelayQueue中来简化时间推进的操作,这样多个时间轮的推进任务只需要一个线程便可完成!
我们之前讲DelayQueue不太适合任务规划,但Kafka时间轮中的Bucket数量并不会很多,在数量不多的情况下DelayQueue性能还是不错的(应该是满足了Kafka的性能需求),所以此处选择了DelayQueue来实现时间的推进。还是应了这句话:没有最好的技术,只有适合的技术。
Kafka的时间轮实现更契合我对超时中心的认知,超时中心只关心时间是否到期并进行回调通知,并不关心和执行任务的情况,Kafka明确了角色分工,所以在海量数据下会更高效。
这里不再贴出源码分析,如果前面几种实现一一看过的话,看Kafka的实现就很容易。
扩展
文章拖的时间太久了,还有两个与定时任务相关的开源项目没来得及看,大家自行看下里面怎么实现定时功能的吧。
总结
这篇文章前后花了一个月的休息时间来做调研和整理,虽然文中有贴出部分源代码,但代码作者的巧妙构思完全不能被表达,还是建议去看源码。
正所谓:纸上得来终觉浅,绝知此事要躬行。
下面给出代码版本:
Rocketmq release-4.5.0
Netty 4.1
Kafka 2.2
JDK 1.8.0_74
小生不才,以上如有描述有误的地方还望各位不吝赐教 !^_^!
参考
如何让快递更”快”?菜鸟自研定时任务调度引擎首次公开
TimingWheel本质与DelayedOperationPurgatory核心结构
Kafka技术内幕样章 层级时间轮
Kafka解惑之时间轮(TimingWheel)
你真的了解延迟队列吗
定时器(Timer)的实现
二叉堆动画展示
二叉树